Here we provide a detailed analysis using more sophisticated statistics techniques.
This comes from the file analysis.qmd.
An Initial Exploration Before Delving into Analysis: Motivation, Interests, Questions
In our pursuit of comprehensively understanding and analyzing the determinants of traffic accidents in Montgomery County, we initiated our investigation by designating “Accident” as the focal point in our dataset. Subsequently, we systematically identified and extracted additional factors we deemed potentially correlated with traffic accidents. Following a meticulous process of data screening and cleansing, we discerned that certain variables held particular significance in influencing the likelihood of accidents. Notably, these pivotal factors encompassed “Race,” “Alcohol,” “Gender,” and “Arrest Type”.
For further analysis, we combined a second dataset from Montgomery County which contained data about traffic violations and selected for race, alcohol/substance abuse, type (crash or traffic violation), and the coordinates of the event. Using census data, the coordinates of the events were displayed over a map showing race proportions by block groups in Montgomery County.
With our overarching objective aimed at generating a comprehensive analysis of traffic accidents, we are interested in examining the correlation between race and traffic events. Furthermore we hope to uncover and analyze any potential racial bias, whether intentional or not, in these traffic violations and accidents, specifically through the possible over-representation of traffic events in the most “non-White” areas. This concept not only harmonizes with the thesis statement established at the outset but also underscores the practical significance of race as the most overtly discernible variable. In a holistic sense, delving into the interplay between race and accidents could help Montgomery identify and reform any unconscious bias and possibly help them implement effective strategies to address this and improve traffic conditions at the same time. Building upon this conceptual foundation, we build our primary analysis direction: “What correlations can be identified between Race and Accident?”
Investigating Correlations Between Race and Traffic Incidents
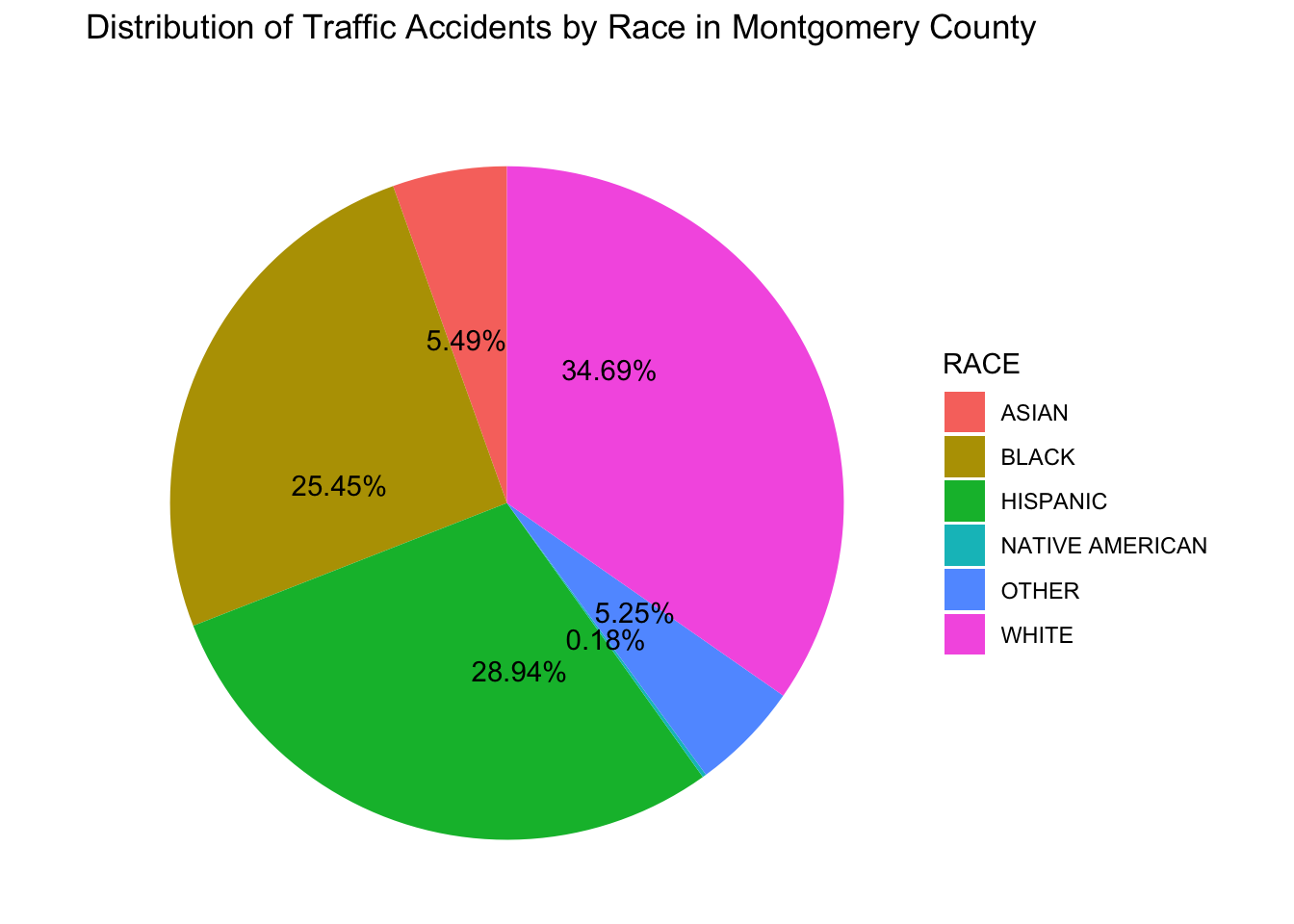
In our gathered datasets, the racial demographics in Montgomery County were delineated into six primary categories: Asian, White, Black, Hispanic, Native American, and other. It is evident that each of these population segments experiences varying levels of accident rates. To delve into the specifics, we sought to ascertain the respective crash rates for each population group, aiming to discern the percentage contribution of traffic accidents within the county. Guided by this objective, we meticulously crafted an initial visual representation in the form of a pie chart.
Figure 1. Distribution of Traffic Accidents by Race in Montgomery County
The pie chart provides a clear visualization of the distribution of traffic accidents by race in Montgomery County. Notably, the largest share is attributed to the White race, comprising 34.69% of all accidents. Following closely, the Hispanic and Black races account for 28.94% and 25.45%, respectively. Conversely, the percentages for Asian, Native American, and other races are notably lower, with Native American accidents registering at just 0.18%. This observed pattern aligns with expectations, given the demographic composition of Montgomery County. Whites, Blacks, and Hispanics, as the predominant ethnic groups, naturally exhibit a higher percentage of accidents due to their larger population size. In contrast, minority groups, such as Asians, contribute proportionally fewer accidents, reflecting their relatively smaller population presence.
Building on the preceding analysis, it is evident that the White ethnicity exhibits the highest percentage of traffic accidents, underscoring its significance as a primary focal point for traffic regulation considerations. While acknowledging this finding, it is essential to recognize that the accident distribution may not provide sufficient insights for formulating valuable recommendations as government initiative references. Therefore, to discover more valuable information, our research focus pivoted toward examining the percentage of traffic accidents within each race. This shift aims to uncover potential disparities in traffic accident rates across different racial groups, fostering a more comprehensive understanding to inform targeted and equitable interventions.
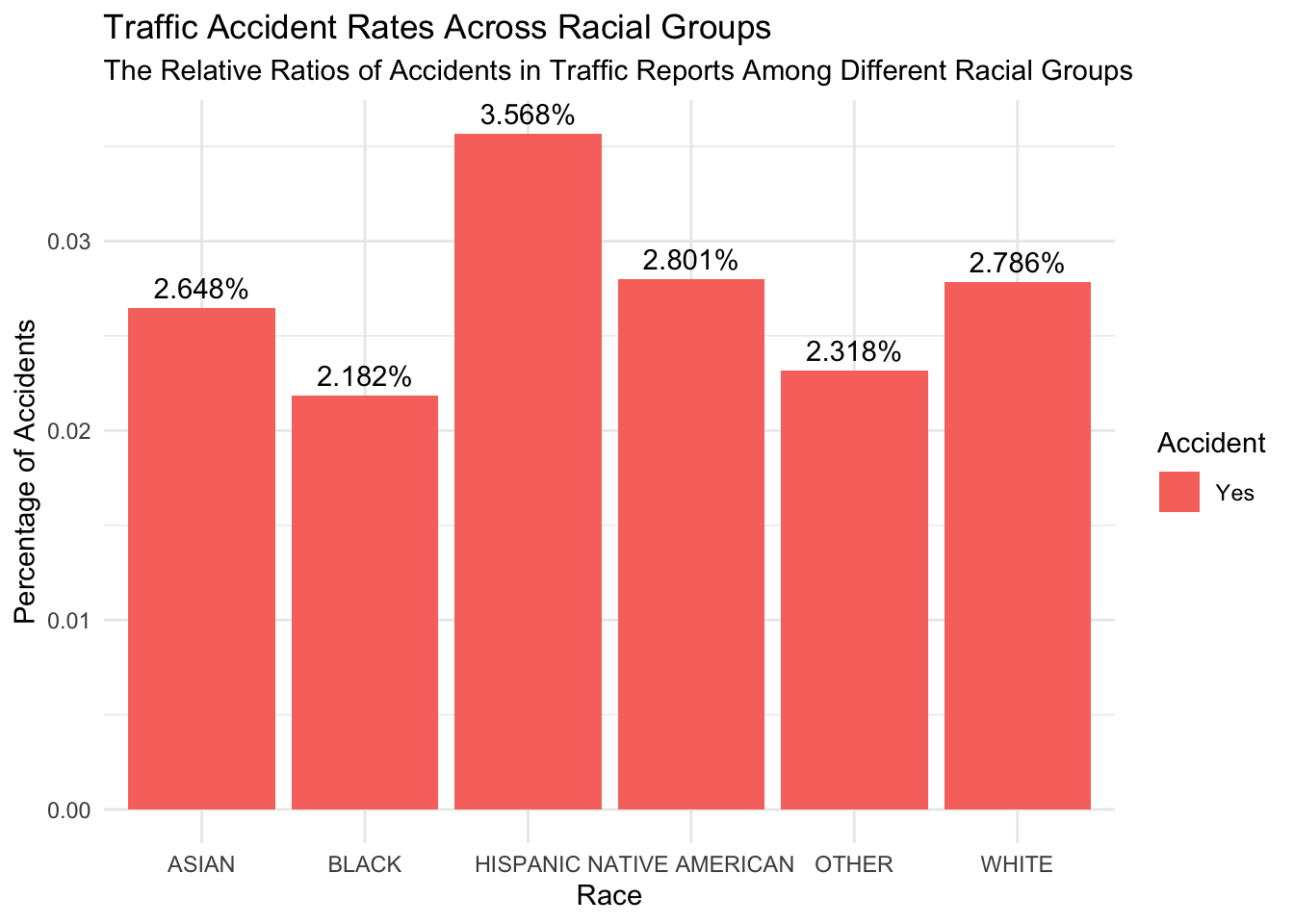
Contengency_table4 <-table(Race,Accident)Contingency_df4 <-as.data.frame(as.table(Contengency_table4))colnames(Contingency_df4) <-c("Race", "Accident", "Count")ratio_df4 <- Contingency_df4 %>%group_by(Race) %>%mutate(ratio = Count /sum(Count))filtered_data <- ratio_df4 %>%filter(Accident =="Yes")Race_Accident_plot <-ggplot(filtered_data, aes(x = Race, y = ratio, fill = Accident)) +geom_bar(stat ="identity", position ="dodge") +geom_text(aes(label = scales::percent(ratio)), position =position_dodge(width =0.8), vjust =-0.5) +labs(title ="Traffic Accident Rates Across Racial Groups",subtitle ="The Relative Ratios of Accidents in Traffic Reports Among Different Racial Groups",x ="Race",y ="Percentage of Accidents") +theme_minimal()Race_Accident_plot
Figure 2. Traffic Accident Rates Across Racial Groups
Figure 2 presents a detailed breakdown of accident rates within each racial category, offering a nuanced perspective distinct from the overall pie chart analyzing accident counts by race. Notably, the accident rate within the White race is comparatively lower at 2.786%, while the Hispanic race exhibits a higher accident rate of 3.568%. This implies that for every 100 traffic reports concerning the Hispanic race, 3.568 accidents are recorded. Further insights reveal that, despite Native Americans and Asians experiencing a lower frequency of accidents, their accident rates are relatively elevated at 2.801% and 2.648%, respectively, in comparison to the corresponding traffic report figures for their ethnicities. Conversely, although the Black ethnic group registers the third-highest number of accidents, its accident rate is the lowest at 2.182%.
From first glance at this data, one might assume that prioritizing Hispanic neighborhoods emerges as an effective strategy to reduce both the total number of accidents and the accident rate. However when we look at the locations of both crashes and violations we see a different trend.
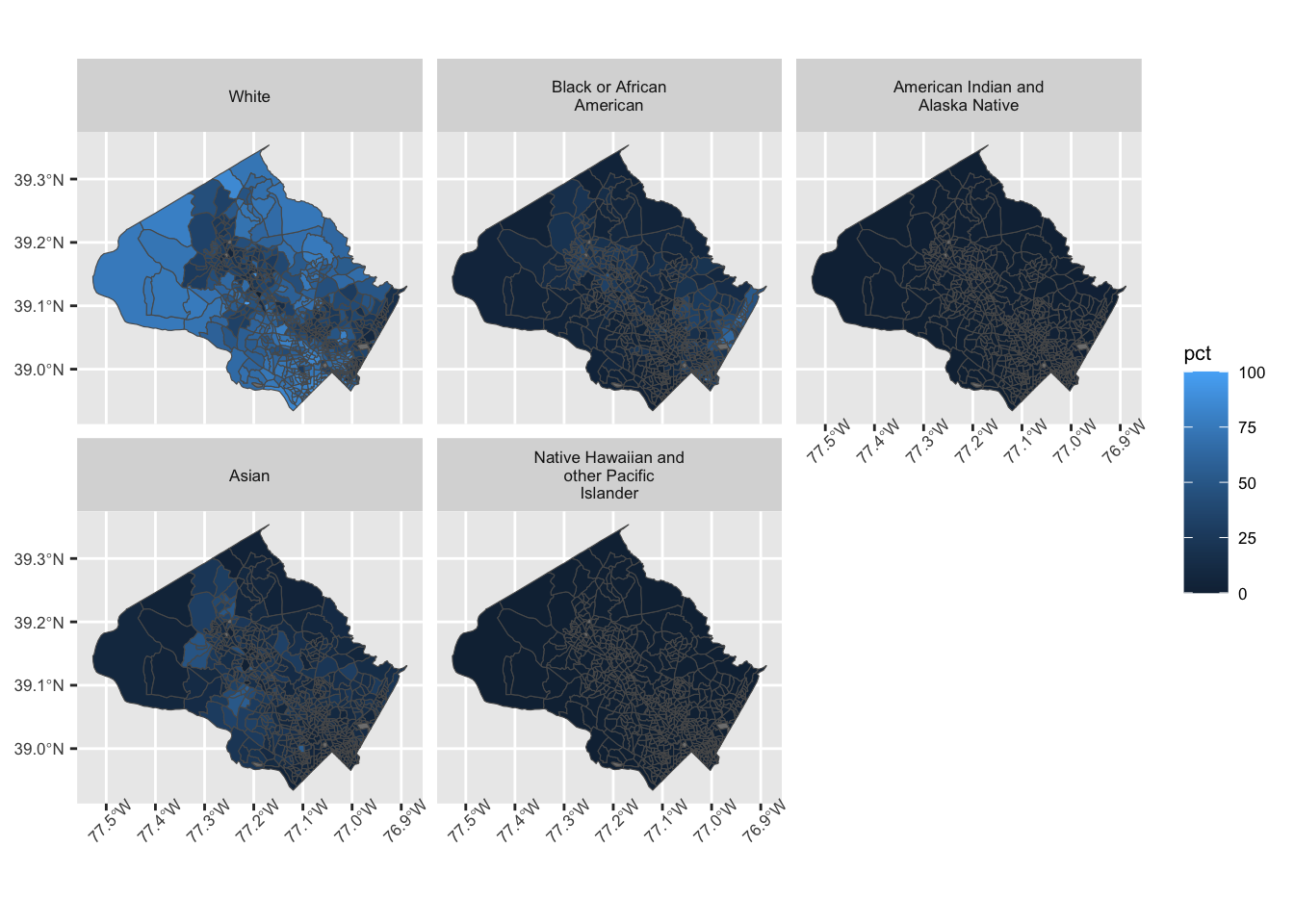
Figure 3. Map of proportion of race by block group for Montgomery County. As we can see from these maps, White people make up a large proportion of Montgomery county.
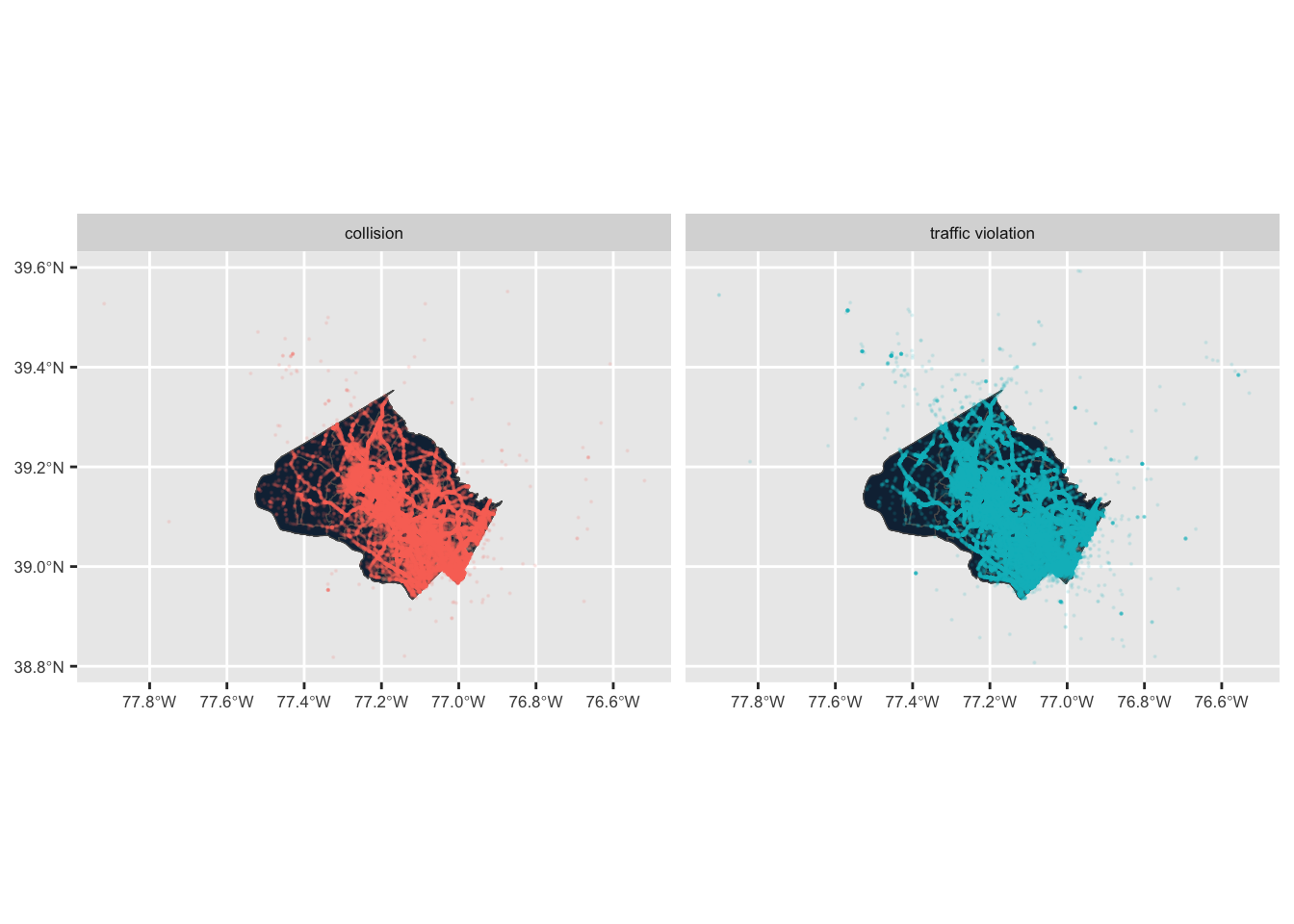
Figure 4. Map of traffic violations (blue) and crash reports (pink). There is a lot of overlap between where the two occur.
Based on Figures 3 and 4, we observe that the areas where people of color make up a higher proportion of the population and the proportion of White people seems to be the lowest, have the most traffic violations and crashes. Therefore the relative percentage of accidents for people of color may be an overestimation because their communities appear to already be policed at a higher rate, and further analysis must be done to account for this.
There could also be many confounding factors in this data that intertwine with race specifically. For example, one interpretation of the data could suggest that there is a need for special preventive measures in ethnic minority Native American communities due to their elevated accident rates. Instead of funding additional policing as a “preventative measure”, perhaps the driver education in communities of color might be inadequate and the government should direct their funding to better driver education programs instead.
With further analysis, we believe our findings could offer valuable insights and allow the Montgomery County government to make better informed decisions about government management, such as reinvesting their funding into community uplifting programs. By tailoring interventions based on the observed patterns, Montgomery County has the potential to address any unconscious bias and enhance traffic conditions, thereby reducing the likelihood of traffic accidents in the future and improving the county for all of its citizens.
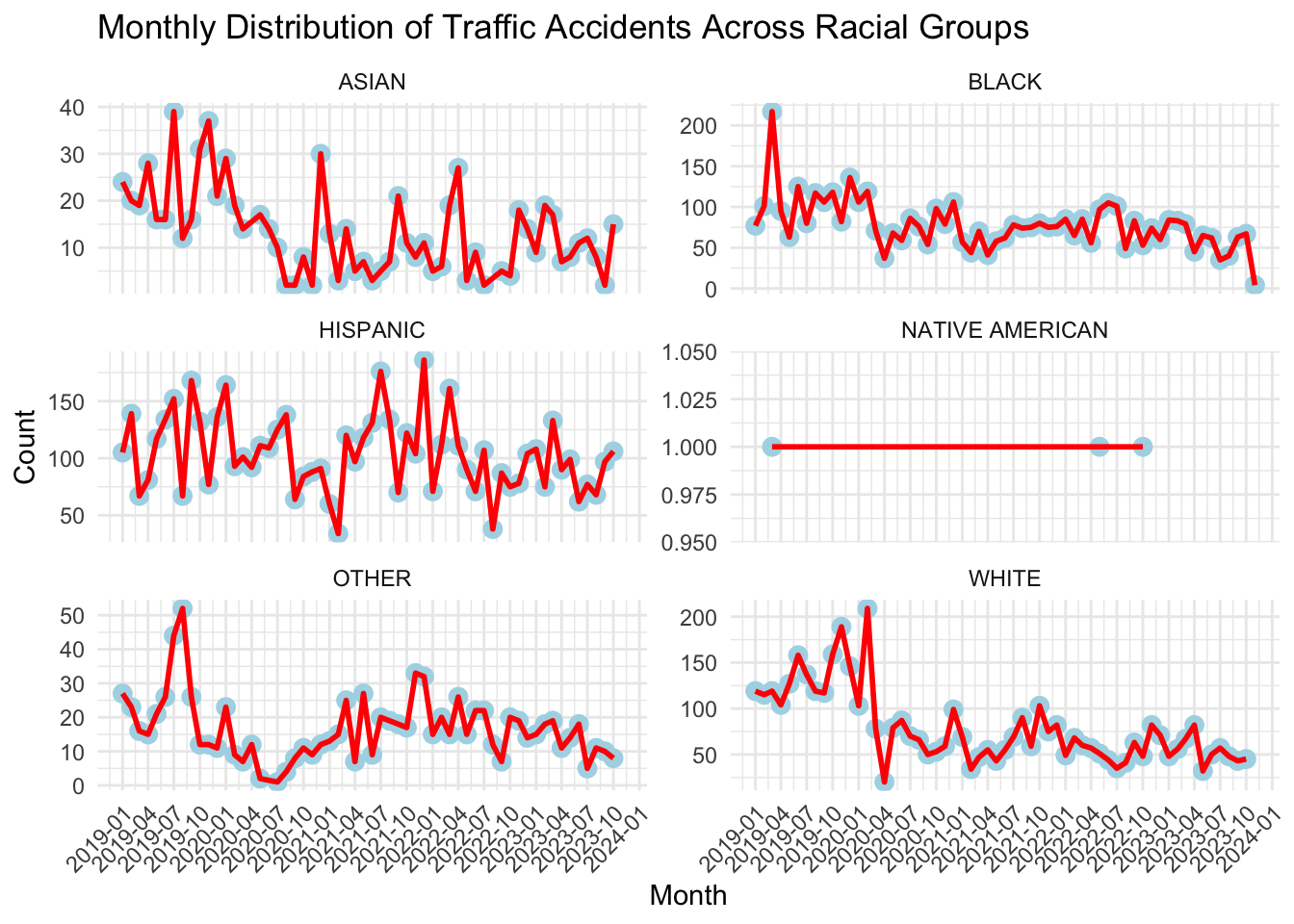
filter_Arrest_type <- df %>%filter(str_detect(`Arrest Type`, "Marked|Unmarked"))filter_Arrest_type$`Arrest Type`<-ifelse(grepl("Marked", filter_Arrest_type$`Arrest Type`), 1, 0)filter_Gender <- filter_Arrest_type %>%filter(str_detect(Gender, "F|M"))mydata <- filter_GenderTime_table <-data.frame(mydata$`Date Of Stop`,mydata$Accident,mydata$Race)Time_table$DateOfStop <-as.Date(Time_table$mydata..Date.Of.Stop., format ="%m/%d/%Y")time_table <- Time_table%>%filter(mydata.Accident =="Yes")colnames(time_table) <-c("Date of Stop", "Accident frequency","Race","Dates")agg_data <- time_table %>%mutate(month_year =format(Dates, "%Y-%m")) %>%group_by(month_year,Race) %>%summarise(Count =n())agg_data_after_2017<- agg_data[451:nrow(agg_data), , drop =FALSE]total_plot <-ggplot(agg_data_after_2017, aes(x =as.Date(paste0(month_year, "-01")), y = Count, group = Race)) +geom_point(color ="lightblue", size =3) +geom_line(color ="red", size =1) +facet_wrap(~Race, scales ="free_y", ncol =2) +labs(title ="Monthly Distribution of Traffic Accidents Across Racial Groups",x ="Month",y ="Count") +theme_minimal() +scale_x_date(date_labels ="%Y-%m", date_breaks ="3 months") +theme(axis.text.x =element_text(angle =45, hjust =1))total_plot
Figure 5. Monthly Distribution of Traffic Accidents Across Racial Groups
To gain a comprehensive understanding of the relationship between race and traffic incidents, we sought to enrich our analysis by integrating additional factors. This approach allows us to explore diverse perspectives and uncover potential patterns. Following a meticulous screening process, we identified “Date Of Stop” as a pivotal time variable. By utilizing this variable, we aimed to construct a meaningful time series plot, focusing on monthly intervals. Simultaneously, given the extensive timeframe of our database spanning from January 2012 to November 2023, we recognize that the analytical significance diminishes with an overly prolonged duration. To maintain the relevance and timeliness of our analysis, we have opted to focus exclusively on the most recent five years of data. Thus, our selected timeframe for constructing the time series plot encompasses data from January 2019 to November 2023.
Upon close examination of the time series plot we generated, a significant trend became apparent: a notable decline in traffic accidents for all race groups, with the exception of the hispanic, starting in 2020. We posit that this noteworthy shift is attributed to the global pandemic sparked by the novel coronavirus in 2019. The widespread impact of the pandemic, coupled with governmental travel restrictions, is believed to have contributed to a substantial decline in travel frequency and, consequently, a noticeable decrease in the overall incidence of traffic accidents.
Moreover, scrutinizing the frequency of traffic incidents post-2020, a noteworthy pattern emerged across all racial groups: a substantial uptick in accidents around January and around July, in contrast to other time periods. Following deliberation, we posit that this observed phenomenon is linked to distinct seasonal trends. Specifically, during January, coinciding with the Christmas holiday season, heightened activities such as shopping, dining, and increased outings likely contribute to the surge in incidents. Similarly, around July, the summer season prompts a notable increase in travel, further influencing the elevated frequency of traffic incidents across diverse racial demographics.
Drawing insights from the aforementioned analysis, we contend that enhancing traffic supervision during the months around January and July can prove effective in mitigating the occurrence of traffic accidents. Simultaneously, considering strategic adjustments to holidays and moderating the intensity of traffic supervision during other periods can assist the government in alleviating management pressures and optimizing administrative efficiency. This nuanced approach aims to strike a balance between bolstering road safety and optimizing resource utilization within the broader framework of traffic management.
Constructing and Analyzing a Logistic Regression Model
After conducting an in-depth examination of the variable “Race,” we recognized that the remaining influential variables were primarily binary variables. Considering the limited depth of analysis achievable through visualization alone, we opted for a unified approach. Our decision involved constructing a comprehensive model to collectively analyze all factors influencing the occurrence of accidents. Given that our dependent variable, “accident”, is also binary, we ultimately selected the logistic regression modeling technique to predict the probability of accidents.
Our finalized model incorporates the following variables:
Independent Variables: Race: Encompassing six categories—White, Black, Asian, Hispanic, Other, and Native American. Alcohol: Categorized as either “Yes” or “No.” Gender: Distinguished between “Male” and “Female.” Arrest Type: Classifying administrative forces into “Marked” and “Unmarked” based on the presence or absence of government markings on the recording vehicles. In the model, “Marked” is denoted as 1, and “Unmarked” as 0.
Dependent Variable: Accident: Assigned a value of 1 for traffic reports indicating an accident (Yes) and 0 for those without an accident (No).
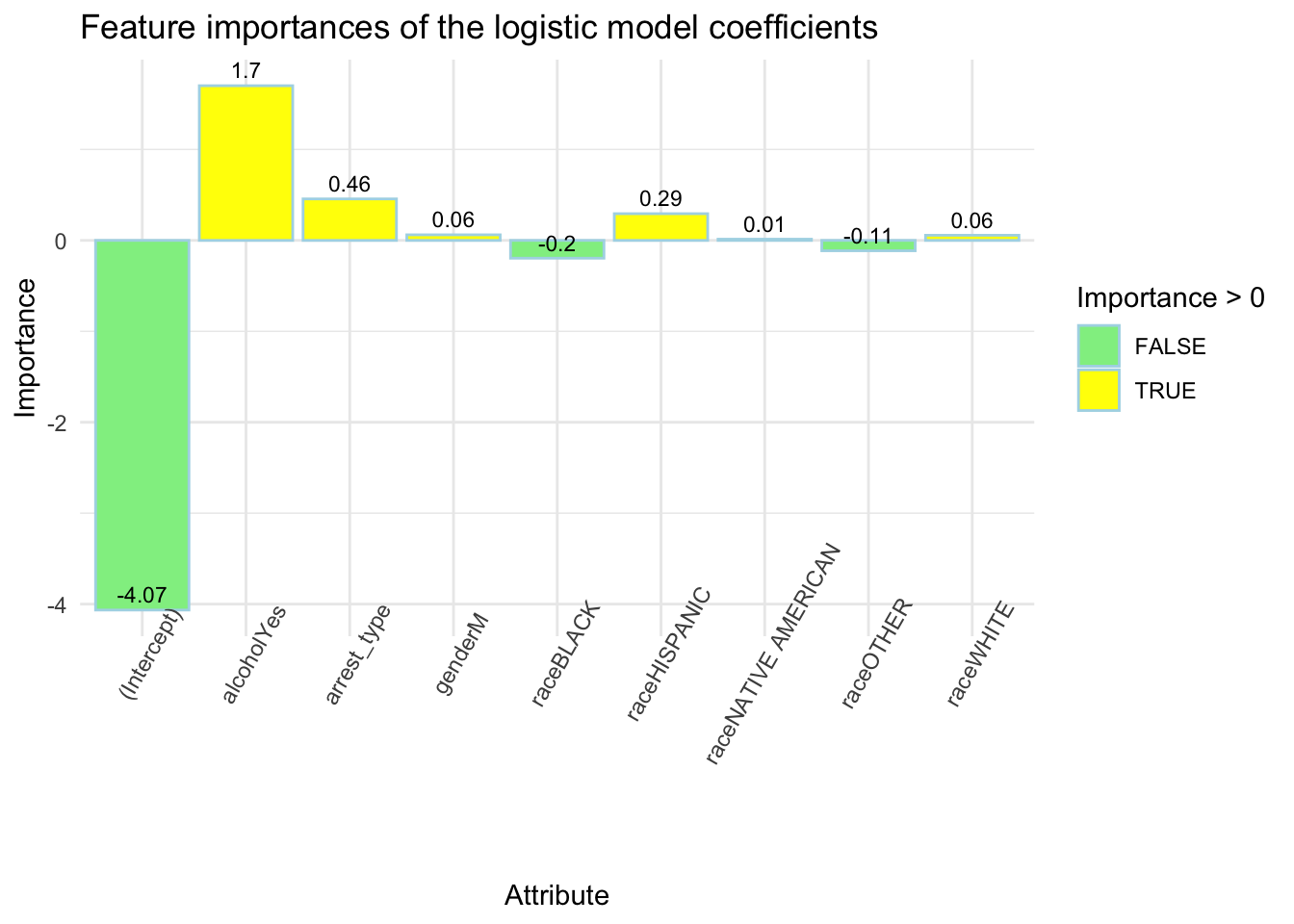
race <- mydata$Racealcohol <- mydata$Alcoholgender <- mydata$Genderarrest_type <- mydata$`Arrest Type`X <-data.frame(race,alcohol,gender,arrest_type)Y <-ifelse(mydata$Accident=="Yes",1,0)split_index <-sample(1:length(race), size =floor(0.8*length(race)))x_train <- X[split_index, ]x_test <- X[-split_index, ]y_train <- Y[split_index]y_test <- Y[-split_index]model <-glm(y_train ~ ., data =cbind(y_train, x_train), family ="binomial")summarytable<-summary(model)# summarytablecoefficients <-coef(model)variable_names <-names(coefficients)importances <-data.frame('Attribute'= variable_names,'Importance'= coefficients)Feature_importance_table <-ggplot(importances, aes(x = Attribute, y = Importance, fill = Importance >0)) +geom_bar(stat ="identity", color ="lightblue") +geom_text(aes(label =round(Importance, 2)), vjust =-0.5, color ="black", size =3) +# Add this linescale_fill_manual(values =c("lightgreen", "yellow")) +labs(title ="Feature importances of the logistic model coefficients") +theme_minimal() +theme(axis.text.x =element_text(angle =60, hjust =0.5)) +xlab("Attribute") +ylab("Importance")Feature_importance_table
Figure 6. Assessing the Significance of Features in the Logistic Regression Model
Considering that the variables analyzed in our model are derived from the traffic report dataset we collected, it’s crucial to acknowledge that accident rates are influenced by a myriad of factors beyond the scope of our dataset, including politics, lifestyle, and traditional culture. Instead of fixating on aspects like model improvements and errors, our emphasis shifts toward understanding the individual impact of each variable revealed by the model on the occurrence of accidents. Building on this foundation, we visually depict the significance of each coefficient in the model, illustrating their positive or negative impact on the accident probabilities.
From Figure 6, first we can observe that the intercept in the logit regression model is substantially negative large, which indicates that the baseline effect of the logit is robust and proves that the probability of error is still relatively small overall.
In examining the selected factors, certain patterns emerge in their impact on the probability of accidents. Notably, instances involving a marked arrest type, the presence of alcohol, male gender, and individuals identified as White, Hispanic, or Native American tend to elevate the probability of accident. Among these variables, the presence of alcohol exerts the most substantial effect, contributing to a 1.62 increase in log-odds. Following closely, marked arrest type and Hispanic Race exhibit the second and third most significant impacts, with effects on log-odds amounting to 0.45 and 0.32, respectively. Moveover, certain factors are associated with a lower likelihood of increased accident rates. Specifically, male, identifying as Native American or White correspond to more modest effects on log-odds, measuring at 0.06, 0.01, and 0.07, respectively. The remaining factors, which generally diminish the probability of accident, exhibit relatively minor effects. Specifically, Black race demonstrates a modest negative effect of 0.19 on log-odds, while the Other race exhibits an even smaller effect of 0.09.
In summary, our logistic regression model highlights distinctive patterns in the impact of various variables on the probability of accident. Female gender, Asian race, unmarked arrest type, and the absence of alcohol do not exhibit a significant influence on accident rates. However, the majority of variables, except for Black Race and Other Race, display a propensity to increase the odds of accidents with a positive effect. This nuanced understanding, derived from our model’s analysis, offers valuable insights for Montgomery County. The findings can serve as a strategic reference point for comprehensively assessing traffic conditions, facilitating informed decisions in traffic scheduling, and guiding initiatives to effectively mitigate the probability of accidents.
Discussion, Conclusions, and Future Directions
In the exploration of the relationship between race and accident, although we are given some influential potential relationships. We think it is important to note that this data is likely biased based on the distribution of police in predominantly White and non-White neighborhoods. The preliminary analysis of the data assumes that the total population is equally distributed across the county and therefore the density of traffic reports and accidents is correlated with race. We believe further analysis is necessary to make any definite conclusions. More detailed data about population distribution and a map of all roads in Montgomery could help provide more insight into the possible effect of race on traffic crashes and violations.
Meanwhile, in our current time analysis, we are limited to a macroscopic examination due to the daily granularity of the traffic records in our collected data. The availability of more granular time data, such as precise records in hours or even minutes, would enable a more detailed analysis of traffic accidents during specific time periods throughout the day. By combining this refined time data with location information, we could extract more nuanced insights. This level of analysis, compared to our current monthly approach, holds a more significant value for the government. It can serve as a valuable reference for scheduling, assisting authorities in fine-tuning duty hours with greater precision. The potential impact is substantial, offering an enhanced ability to minimize and prevent traffic accidents to the greatest extent possible.
In the realm of model construction, a notable limitation arises from the categorical nature of all our independent variables, without the support of numerical counterparts. Consequently, the interpretive scope of our model may be constrained. Additionally, considering that the target variable accidents represent rare occurrences, the seemingly high prediction accuracy may not necessarily reflect the model’s robustness. This limitation becomes apparent through the unsatisfactory AUC score and ROC curve results. To bolster the credibility and reference value of our model, two key aspects demand focused attention. Firstly, addressing the impact of the small probability event within the target variable is imperative. This involves refining our model to mitigate the challenges associated with the rarity of the analyzed accidents. Secondly, the pursuit of additional numerical independent variables is paramount. Introducing more numerical variables into our model construction process can enhance its predictive capabilities and offer a more comprehensive understanding of the underlying patterns. Both objectives lead to a potential for reanalysis of the database, possibly incorporating additional data to fortify the model’s robustness and effectiveness.
In summary, our analysis indicates a notable correlation between crash probability and race in Montgomery County, revealing a significantly higher incidence of crashes among the white population compared to other races. Additionally, varying degrees of correlation emerge between the probability of being involved in a traffic accident across the county and several factors, including alcohol involvement, gender, and arrest type. Looking ahead, our outlook involves a commitment to collecting more detailed data, integrating diverse databases, and conducting comprehensive analyses. This approach aims to deepen our understanding and provide a more detailed perspective on the factors influencing traffic accidents in Montgomery County.